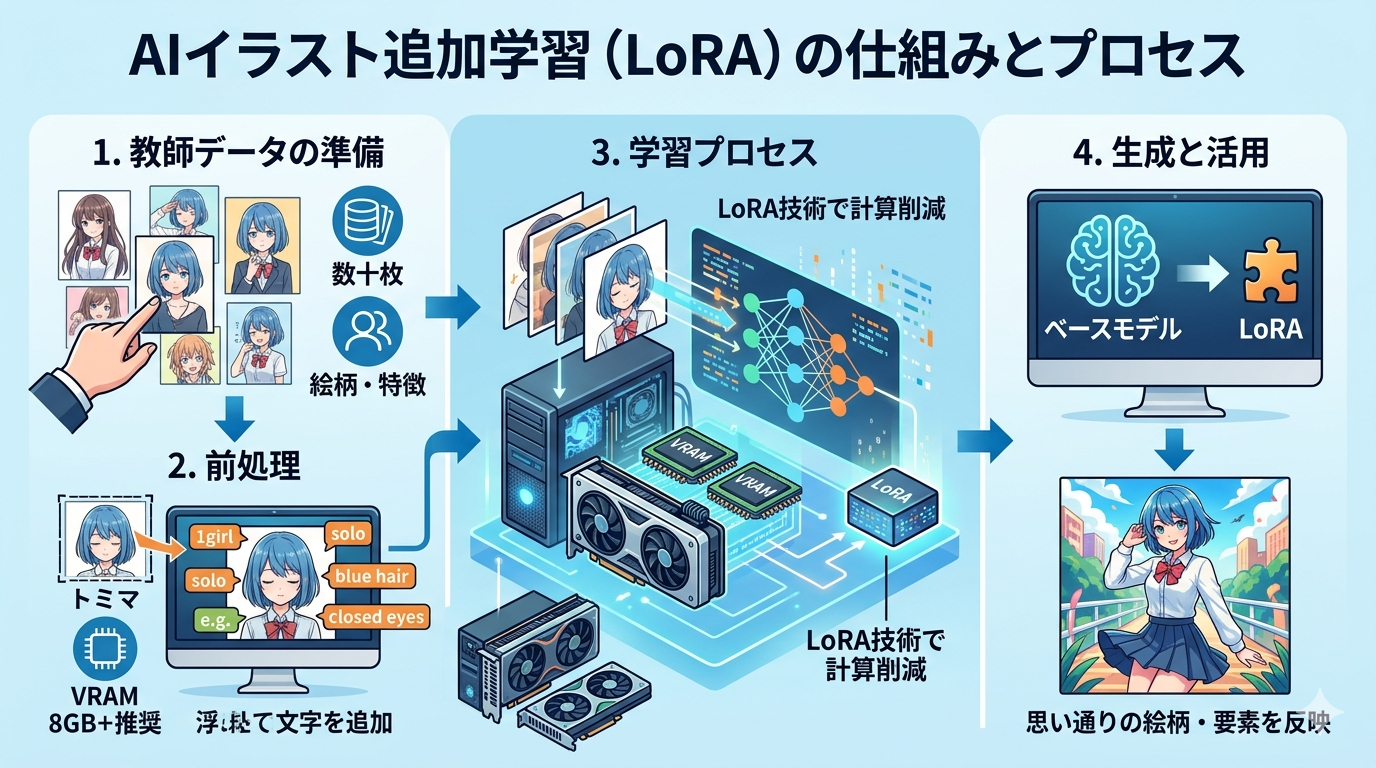
近年の目覚ましいテクノロジーの発展により、画像生成という分野はかつてないほどの大きな転換期を迎えていると言えるかもしれません。入力したテキストの指示に応じて、多彩で高品質な画像が瞬時に生み出されるこの技術は、クリエイターのみならず多くの人々の関心を集めていると考えられます。しかし、あらかじめ用意された標準的なモデルを使用し続けていると、次第に「もっと自分好みの絵柄に近づけたい」「特定のキャラクターやアイテムのデザインを正確に反映させたい」といった新たな要望が高まってくるのは自然な流れであると推測されます。
このような特定の要素や画風をシステムに取り入れるプロセスは、一般的に「追加学習」という言葉で表現されることが多いようです。しかしながら、このプロセスは非常に専門的な知識を要する部分があり、一見すると初心者にはハードルが極めて高いように感じられるかもしれません。どのような仕組みの裏付けがあって特定の絵柄が反映されるようになるのか、そして実際に自分の手で取り組む場合にはどのような手順を踏み、どのような作業環境を整える必要があるのか、多くの疑問を抱く方も少なくないのではないでしょうか。
本記事では、特定の絵柄や要素を反映させるためのプロセスについて、その技術的な仕組みや必要となる事前の準備、さらには実行する上で注意すべき点などを多角的な視点から幅広く調査し、詳細に考察していきたいと考えております。決してこれといった一つの絶対的な正解が存在するわけではない複雑な領域ではありますが、現在主流となっていると思われる手法や考え方を探ることで、皆様の創作活動における新たな可能性の扉が開かれるかもしれません。
- 基礎知識として知っておきたいaiイラストに学習させる方法の仕組み
- ベースモデルに対する追加学習という概念の概要かもしれない点
- LoRAと呼ばれる技術が広く普及している理由と推測される背景
- 準備すべき画像データとなる教師データの質と量に関する一般的な見解
- 処理を実行するために求められるパソコンのスペック環境の目安と考えられるもの
- 実践的な視点から考察するaiイラストに学習させる方法と具体的な手順
- 素材となる画像の収集とトリミングなどの前処理が持つ重要性について
- キャプション付けと呼ばれるタグ作業が最終的な出力に与える影響の可能性
- 専用の学習ツールやインターフェースの導入における複雑さについての考察
- パラメータの設定と生成されたファイルのテストという試行錯誤のプロセス
- 実行前に確認しておきたいaiイラストに学習させる方法における注意点と課題
- 著作権や他者の権利に関わる法的な解釈と倫理的な配慮の必要性
- 過学習と呼ばれる現象が起きてしまう原因と対策の推測
- ノイズの混入や意図しない特徴の反映といった失敗例から学べるかもしれないこと
- 高スペックなパソコンを持たない場合のクラウドサービスという代替手段の可能性
- aiイラストに学習させる方法についてのまとめ
基礎知識として知っておきたいaiイラストに学習させる方法の仕組み

ベースモデルに対する追加学習という概念の概要かもしれない点
画像生成のシステムに特定の要素を覚えさせるプロセスを理解するためには、まず基盤となる「ベースモデル」と、それに対する「追加学習」という関係性を把握することが重要であると考えられます。ベースモデルは、すでに膨大な量の画像データを読み込み、一般的な物体や風景、人物などの特徴を幅広く理解している状態にあると推測されます。しかし、それはあくまで汎用的な知識であり、個人の特定の好みやニッチなキャラクターのデザインまでは網羅していない可能性が高いと言えるでしょう。
そこで用いられるのが追加学習と呼ばれるアプローチのようです。これは、すでに賢く育っているベースモデルに対して、特定のテーマに絞った画像データを集中的に見せることで、「この特定のキーワードが入力された時には、この特定の絵柄や特徴を優先して出力する」という新しいルールを上書き、あるいは追加する作業であると解釈できるかもしれません。例えるなら、一般的な教養を身につけた学生に対して、特定の専門分野の特訓を施すようなものだと考えるのが分かりやすいのではないでしょうか。この技術により、ゼロから膨大な時間をかけてモデルを作り直すことなく、効率的に目的の出力を得られる可能性が高まるとされています。
LoRAと呼ばれる技術が広く普及している理由と推測される背景
追加学習の手法の中でも、近年特に大きな注目を集め、広く普及していると言われているのがLoRAと呼ばれる技術のようです。この技術がこれほどまでに支持されている背景には、従来のファインチューニングと呼ばれる手法が抱えていた大きな課題を解決できる可能性を秘めているからだと推測されます。従来の手法では、ベースモデル全体の複雑なネットワークの数値を直接書き換える必要があり、これにはスーパーコンピューター並みの膨大な計算資源と長い時間が必要であったと言われています。
一方、LoRAという手法は、ベースモデルそのものには直接手を加えず、その上に非常に薄い「追加のフィルター」や「差分データ」のようなものを被せる仕組みを採用していると考えられています。これにより、計算量が劇的に削減され、一般的な個人向けのパソコン環境であっても、現実的な時間内で処理を完了させることができるようになったという見方が強いようです。さらに、作成されたデータファイルは非常に容量が小さく、複数のデータを切り替えたり、組み合わせたりして使用することが容易であるという利便性の高さも、多くのユーザーに受け入れられている大きな要因であると言えるでしょう。
準備すべき画像データとなる教師データの質と量に関する一般的な見解
システムに新しい特徴を覚えさせるためには、お手本となる画像データ、いわゆる「教師データ」を用意する必要があると考えられます。この教師データの質と量が、最終的な出力結果のクオリティを決定づける最も重要な要素であると指摘する声も少なくないようです。枚数に関しては、学習させたい対象の複雑さによっても変動すると思われますが、一般的には数十枚から百枚程度の画像が推奨されるケースが多いと推測されます。少なすぎると特徴を十分に捉えきれない可能性があり、多すぎても処理に時間がかかるばかりか、かえって特徴がぼやけてしまうリスクがあると言われているようです。
また、量以上に重要視されているのが画像の「質」と「一貫性」であると考えられます。例えば、特定のキャラクターの顔を覚えさせたい場合、様々な角度から描かれた顔の画像や、異なる表情の画像をバランス良く揃えることが効果的であると推測されます。しかし、画風がバラバラであったり、解像度が極端に低かったり、無関係な背景やノイズが多く含まれていたりすると、システムが「どの部分を学習すべき重要な特徴なのか」を混乱してしまい、結果として質の低い出力につながってしまう可能性が高いと危惧されています。
処理を実行するために求められるパソコンのスペック環境の目安と考えられるもの
実際に自分の手元の環境で追加学習の処理を実行しようと考えた場合、パソコンの性能、特にグラフィックボードのスペックが非常に高い壁として立ちはだかる可能性が高いと考えられます。画像生成の処理自体も重い作業ですが、システムに新しいデータを計算させて重みを調整する作業は、それ以上に膨大な計算負荷を伴うと言われているからです。
一般的に、この処理を安定して行うためには、グラフィックボードのVRAMと呼ばれるメモリの容量が最低でも8ギガバイト、可能であれば12ギガバイト以上搭載されていることが推奨されるケースが多いと推測されます。もしVRAMの容量が不足していると、処理の途中でエラーが発生して強制終了してしまったり、極端に長い時間がかかってしまったりする可能性が非常に高いと考えられます。そのため、本格的に取り組む前には、自身のパソコンのスペックが要件を満たしているかを慎重に確認することが、失敗を防ぐための第一歩になるのではないでしょうか。
実践的な視点から考察するaiイラストに学習させる方法と具体的な手順
素材となる画像の収集とトリミングなどの前処理が持つ重要性について
準備段階として集めた画像データは、そのままの状態でシステムに読み込ませるわけではなく、適切な形に整える「前処理」という工程を経る必要があると考えられています。この工程をどれだけ丁寧に行うかが、最終的な精度を大きく左右するかもしれないと言っても過言ではないと推測されます。まず行われることが多いのが、画像の解像度を統一し、正方形などの特定の比率に切り抜く「トリミング」と呼ばれる作業のようです。
システムは特定のピクセルサイズの画像を最も効率的に処理できるように設計されていることが多いため、あらかじめ512ピクセルや768ピクセルといった規定のサイズに綺麗に収まるように画像を調整することが求められると考えられます。さらに、学習させたい対象物以外の余計な情報を取り除く作業も重要視されているようです。例えば、キャラクターの顔だけを学習させたいのであれば、背景に写っている無関係な風景や、他のキャラクター、あるいは文字や透かしロゴなどを可能な限り排除しておくことで、システムが純粋に目的の対象物だけに集中して特徴を抽出できるようになる可能性が高まると推測されます。
キャプション付けと呼ばれるタグ作業が最終的な出力に与える影響の可能性
画像の前処理が完了した後に行われるのが、それぞれの画像が「何を描いているのか」をシステムに言葉で説明するための「キャプション付け」または「タグ付け」と呼ばれる作業であると考えられます。システムは画像を見ただけではそれが何であるかを言語的に理解できないため、人間がテキストで補足情報を与えてあげる必要があると推測されます。この作業は非常に奥が深く、タグの付け方一つで出力される結果が劇的に変化する可能性を秘めていると言われています。
例えば、「赤い髪の少女」の画像を学習させる際、単に「少女」というタグだけを付けた場合、システムは「赤い髪」という要素も「少女」という概念の必須条件の一部として固く結びつけて覚えてしまうかもしれないと考えられます。その結果、後から「青い髪の少女」を出力しようとしても、常に赤い髪になってしまう現象が起こり得ると推測されます。これを防ぐためには、「赤い髪」「少女」と要素を分解してタグ付けを行うなど、システムにどこまでを固定の特徴として捉え、どこからを変更可能な要素として扱うかをコントロールする高度なテクニックが求められる傾向にあるようです。
専用の学習ツールやインターフェースの導入における複雑さについての考察
前処理とキャプション付けが完了したデータを実際にシステムに計算させるためには、専用のソフトウェアやツールをパソコンに導入する必要があると考えられます。現在、有志のエンジニアたちによって開発された様々なツールがインターネット上で公開されているようですが、これらを自身の環境に構築する作業は、決して直感的で簡単なものではない可能性が高いと推測されます。
多くのツールはプログラミング言語であるPythonをベースに動いているため、専用の実行環境を構築したり、必要な関連ライブラリをコマンド入力でインストールしたりする作業が求められるケースが多いと考えられます。黒い画面に文字を打ち込む操作に慣れていない方にとっては、この導入段階でつまずいてしまうことも少なくないのではないでしょうか。最近ではマウス操作で設定できる画面を備えたツールも増えてきているようですが、それでも初期設定の複雑さや、エラーが出た際の自己解決能力が一定レベルで求められるという側面は依然として残っていると言えるかもしれません。
パラメータの設定と生成されたファイルのテストという試行錯誤のプロセス
ツールの準備が整い、いざ学習を開始する段階になっても、ただボタンを一度押せば理想的な結果が得られるというわけではないと考えられます。システムにどのようなペースで、どの程度の深さまでデータを記憶させるかを指示するための、様々な「パラメータ」を設定する必要があるからです。例えば「学習率」と呼ばれる数値が高すぎると特徴が壊れてしまい、低すぎると一向に特徴を覚えてくれないというジレンマに陥る可能性があると推測されます。
また、「エポック数」や「ステップ数」と呼ばれる学習の反復回数も重要な指標となるようです。これらの設定には万能な正解は存在せず、用意した画像の枚数や質によって最適な数値が常に変動すると考えられています。そのため、最初は仮の数値で学習を実行し、生成された中間ファイルを実際に読み込んで画像を生成するテストを行い、その結果を見ながら再び数値を微調整してやり直すという、地道な試行錯誤のプロセスを何度も繰り返すことになるのが一般的であると推測されます。根気強さと観察力が求められる作業であると言えるでしょう。
実行前に確認しておきたいaiイラストに学習させる方法における注意点と課題
著作権や他者の権利に関わる法的な解釈と倫理的な配慮の必要性
他者の作品や写真を教師データとして使用し、システムに読み込ませる行為については、著作権法などの法的な解釈が非常に複雑に絡み合う問題であると考えられています。多くの国や地域において、情報解析や技術開発を目的とした限定的な範囲内での利用であれば、一定の条件下で著作権の侵害には当たらないとする例外規定が存在するケースもあるようですが、その解釈は常に議論の的となっていると推測されます。
法的にグレーゾーンではないと判断される場合であっても、クリエイターの感情や倫理的な観点から強い反発を招く可能性は十分に考えられるのではないでしょうか。特定の個人の画風を無断で模倣して大量に生成し、それを公開したり販売したりする行為は、元のクリエイターの利益を不当に害する恐れがあると指摘されています。そのため、データを使用する際には、提供元が明示している利用規約を熟読することはもちろんのこと、常に他者の権利と労力に対する深い敬意と倫理的な配慮を持ち続けることが、この技術を扱う者にとって最も重要な責任であると言えるでしょう。
過学習と呼ばれる現象が起きてしまう原因と対策の推測
学習のプロセスにおいて非常に頻繁に遭遇する厄介なトラブルの一つが「過学習」と呼ばれる現象であると考えられます。これは文字通り、システムが与えられた教師データを「覚えすぎてしまった」状態を指すと推測されます。本来、システムには様々なプロンプト(指示文)に応じて柔軟に画像を変化させる能力が求められますが、過学習を起こしたモデルは、教師データと全く同じ構図や表情しか出力できなくなってしまい、応用力が完全に失われてしまう可能性が高いと言われています。
この現象の原因は、学習の反復回数が多すぎたり、学習率の設定が高すぎたりすることにあると考えるのが自然かもしれません。また、用意した画像データがすべて同じような構図であった場合も、システムが「この構図でなければならない」と誤って強く認識してしまう原因になり得ると推測されます。対策としては、学習の途中で定期的に生成結果を確認して適切なタイミングで処理を打ち切ることや、様々な角度やポーズを含む多様な画像をデータセットに混ぜ込むといった工夫が有効であると考えられています。
ノイズの混入や意図しない特徴の反映といった失敗例から学べるかもしれないこと
教師データの質が不十分であったり、キャプションの付け方に不備があったりした場合、生成される画像に意図しない「ノイズ」や不自然な特徴が混入してしまう失敗例も数多く報告されているようです。例えば、集めた画像の大半に特定のブランドのロゴや、不要なサインが薄く写り込んでいた場合、システムはそれらも「再現すべき重要な特徴の一部」であると勘違いしてしまい、生成するすべての画像に謎の模様を描き込んでしまう可能性が考えられます。
また、顔の特徴だけを覚えさせたかったのに、教師データの多くが特定の暗い照明下で撮影されたものであった場合、生成される画像全体が常に暗く淀んだ色調になってしまうといった、環境要因の意図しない学習も起こり得ると推測されます。これらの失敗から学べることは、システムは人間のように「空気を読んで」不要な部分を無視してくれるわけではないという事実かもしれません。システムに入力する情報は、人間が責任を持って徹底的に精査し、純度を高めておく必要があるという教訓を示していると言えるのではないでしょうか。
高スペックなパソコンを持たない場合のクラウドサービスという代替手段の可能性
前述したように、自前の環境で処理を実行するためには非常に高価なパソコンが必要となるケースが多いと考えられますが、そのような環境を用意できない場合でも諦める必要はないかもしれません。インターネットを経由して、外部の強力なサーバーの計算能力を一時的に借りる「クラウドサービス」を利用するという代替手段が存在すると推測されるからです。
これらのサービスを利用すれば、手元のパソコンは単なる操作用の画面として機能するだけで済むため、低スペックのノートパソコンや、場合によってはタブレット端末からでも高度な学習処理を実行できる可能性が開かれます。利用時間に応じた従量課金制や、定額のサブスクリプション制など様々な形態があるようですが、機材を丸ごと買い換えるのに比べれば、初期費用を大幅に抑えられるメリットがあると考えられます。ただし、サービスごとに使い方の作法が異なったり、データを外部のサーバーにアップロードする際のセキュリティポリシーなどを確認したりする手間が発生するという側面も考慮しておく必要があるでしょう。
aiイラストに学習させる方法についてのまとめ
今回はaiイラストに学習させる方法についてお伝えしました。以下に、今回の内容を要約します。
・ベースモデルに特定の要素を記憶させる追加の処理が存在すると考えられる
・LoRAという技術が計算負担を軽減する手法として広く普及しているようである
・用意する教師データの質と一貫性が最終的な完成度を大きく左右する可能性がある
・VRAM容量の大きい高性能なグラフィックボードが必要となるケースが多いと推測される
・画像の解像度統一や不要な部分を取り除く事前のトリミング作業が重要となるかもしれない
・画像の内容を言葉で説明するキャプション付けが仕上がりをコントロールする鍵になり得る
・専用ツールの導入にはコマンド操作などの一定の専門知識が求められる傾向がある
・学習率や反復回数などのパラメータ調整は試行錯誤を繰り返す必要があると考えられる
・他者の作品を利用する際は著作権などの法的な解釈への慎重な配慮が不可欠である
・覚えさせすぎによる過学習を防ぐために適切な段階で処理を止める見極めが必要となる
・教師データに含まれる意図しないノイズや模様まで反映されてしまう失敗例があるようである
・自前のパソコンの性能が不足している場合はクラウドサービスの活用が代替手段となり得る
以上の調査から、画像を生成する技術を自身の好みに合わせてカスタマイズする手法は、非常に奥深く複雑な要素が絡み合っていると考えられます。専門的な知識や試行錯誤が求められる分野ではありますが、仕組みを理解し適切な手順を踏むことで、独自の表現を獲得できる可能性を秘めているのではないでしょうか。法的なルールや倫理的な配慮を常に心がけながら、新しい技術の動向を注視していくことが、今後の健全な創作活動において重要な意味を持つと言えるでしょう。

コメント